
女子在早市发药品小广告 你瞅瞅,这小广告上都写了些啥!这哪里还是广告,简直比黄色小说还黄!近日,市民张先生向沈阳晚报、...

6月13日,由中国电影电视技术学会主办的“菁彩视界·智享未来”2024北京国际电视技术研讨会在京举办。来自国家广播电视总局、中央广播电视总台、全国多家广播电视台的领导、行业专家学者以及创新技术企业的500余名代表共襄盛会,共同推进“超清化、移动化、智能化”创新技术应用发展。在开幕式暨主旨报告会上,华为受邀参加,华为云北京产品中心总经理杨辉发表了《盘古大模型在传媒领域的应用探索》的主题演讲,分享了华为云盘古大模型解决方案及其在传媒领域的诸多应用场景和实践效果。

【2024ITTC 主旨报告会】
生成式AI,正在用技术重塑艺术创作
近年来,超高清视听与5G、人工智能、虚拟现实等新一代信息技术深度融合创新发展,催生大量新场景、新应用、新模式,成为千行百业数字化转型的重要赋能力量。绘画、雕塑、摄影、音乐、舞蹈、戏剧、文学和影视艺术等多种艺术形态的创作方式正在发生变化,生成式AI正在用技术重塑艺术创作。
在生成式AI时代,创作流程得以改变,以往需要长时间验证和高门槛的创意过程,现在可以通过AI辅助快速生成内容。例如,使用盘古多模态大模型,就可以实现以文生图、以图生图甚至文生视频和图生视频的功能。这降低了艺术创作的入门难度,使得只要有创意,任何人都能创作自己的艺术作品。
更多模态,多维感知,万物理解,开启AIGC新范式
相较于“文本理解世界”的大模型,盘古多模态大模型的优势在于能够通过更多模态理解世界,如图像、视频、语音、3D、时序数据等。盘古多模态大模型的主要优势,还在于模型架构稳固且支持增量扩展,能够轻松融入音频、视频等多种模态,并通过高效的模态对齐方式持续沉淀知识。增量扩展模态的开销大幅全量训练,显著降低成本。同时,模型能力多样且不断提升,涵盖了基础、高阶和专家能力,支持多尺度视觉表征提取和高分辨率编码器,满足客户各种模型开发需求。与此同时,还提供零代码模型开发全流程工具,让使用更加便捷。在训练和推理方面,追求持续降本增效,全栈AI自主创新,可确保模型量化效果降幅微小。
杨辉在主题演讲中指出,盘古多模态大模型具有多个典型应用场景,例如在内容审核方面,如文本、图片、音频、视频的全栈式审核,保障信息安全;在内容创作上,辅助文案生成,提升创作效率;在知识问答和文档助理场景下,提供准确的信息查询和文档处理服务;在城市治理和智慧医疗领域,发挥着数据分析和决策支持作用;在视觉问答、常识推理和色彩感知等视觉任务中表现优秀;并能进行关系推理、数量感知以及空间推理等复杂的认知任务。此外,模型在遥感、视频分析、行为识别、场景识别、实体识别以及OCR等方面均有涉及,显示了其广泛的应用潜力。
在图像生成方面,人工智能在艺术创作中展现出强大的创新力,包括概念注入、以图生图和以文生图等多种形式。图像理解是多模态全栈式内容审核的关键部分,利用先进的计算机视觉(CV)技术和自然语言处理(NLP)技术,对文本、图片、音频、视频和直播内容进行全面审核。在影视工业生产中,AI世界模型正助力高真实感、低成本的虚拟拍摄,逐步替代绿幕和3D引擎技术,通过AI生成的虚拟内容与实拍镜头融合,提供更加自然的演员表演环境。此外,视频生成技术也在自动驾驶场景数据生成和具身智能机械臂操作视频生成中发挥作用,提高了数据生成的效率和质量。
科技赋能发展,创新决胜未来。盘古多模态大模型以其强大的能力,展现了多模态理解世界的广阔前景。通过更多模态的感知,模型能够更好地理解世界,实现更高效、更准确地创作和审核。展望未来,华为将继续携手伙伴共同推进“超清化、移动化、智能化”创新技术应用的落地,华为盘古大模型将为AIGC可信高效发展注入强劲动力,为智能世界带来更多可能。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
女子在早市发药品小广告 你瞅瞅,这小广告上都写了些啥!这哪里还是广告,简直比黄色小说还黄!近日,市民张先生向沈阳晚报、...

近日,笔者在江苏省常州市街头,看到在路上行驶的一辆面包车,该车的车后窗玻璃破了,整个车后窗玻璃是用硬...
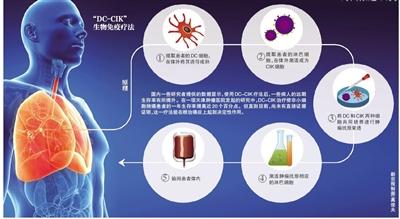
魏则西在武警北京二院使用的是DC免疫治疗技术属于细胞免疫疗法的一种。业内人士坦言,虽然DC-CIK疗法在国内...

□通讯员 鼓公宣 赵柏恋茹 党晨 金陵晚报记者 徐宁 《加菲猫》 是一部脍炙人口的经典动画片,现...

昨日,朝阳高碑店一饭店煤气罐爆燃。饭店玻璃大门被炸毁,门口一辆黑色轿车后窗玻璃被砸坏。新京报记者 尹...